
Parks and Recreation(al Mathematics)
Continuing last week's trend of discussing mathematics in the context of NBC comedy, today I'd like to move from The Office to Parks and Recreation. More specifically, I'd like to discuss local government wunderkind/aspiring club owner Tom Haverford, whose unique charm I cherish almost as much as Ron Swanson's mustache.

What a stud.
In a recent episode, Tom Haverford waxed poetic on the slang he has invented to describe different types of food. A clip is currently on YouTube (though I don't know how long it will stay).
Here's a list of the slang Tom uses:
desserts = 'serts,
entrees = tre-tre's,
sandwiches = sammies, sandoozles, or adamsandlers,
cakes = big ole' cookies,
noodles = long-ass rice,
fried chicken = fry-fry chicky-chick,
chicken parm = chicky-chicky parm-parm,
chicken cacciatore = chicky catch,
eggs = pre-birds or future birds,
root beer = super water,
tortillas = bean blankies.
Some folks had the brilliant idea to build on this new parlance by creating a website devoted to related slang that Tom Haverford might use. The website, tomhaverfoods.com, consists of one of several delightful pictures of Mr. Haverford, followed by a food item and an appropriate slang term. Click on Tom's face and you'll get a new term.

Watch out, ladies!
Here is where the math comes in: the slang items aren't numbered, so one can't be certain when one has seen all of these inspired terms. Since the slang terms are (presumably) generated randomly, even if you click on Tom 1,000 times, there is a chance that there will be one slang term that simply hasn't appeared. The issue is further complicated by the fact that the volume of slang terms is surely growing (there is a link on the website for people to submit slang suggestions), but let me ignore this issue for now and simply assume that the website contains a fixed number (say N) slang terms, and when you click on Tom's face, one of those slang terms is selected at random to display.
Consider the following experiment: go to the website, and record the slang term that awaits you. Then click on Tom's face and record the next slang term. Repeat this process until you encounter a slang term you've already recorded, and then stop. This will give you a list of slang terms (say k of them). The question, then, is the following: can we use k to estimate N? In other words, can we use the number of unique slang terms we see to estimate how many total slang terms are on the website?
We can model this situation with some probability. Let's start with some preliminary analysis. First, note that if there are N phrases on the website, the worst case is that you will get only one term, and the best case is that you obtain all N (this happens if you are lucky enough to have no repeats until you've seen every possible phrase, so that page view N + 1 must be a repeat, since there are only N total phrases - this is the pigeonhole principle at work).
Now, you will obtain only one slang term if the second term is the same as the first; since there are N terms total, the probability of the second term being the same as the first term is 1/N. What about the probability that you obtain two terms? This happens only if the second term is different from the first, but the third term is one of the previous two. Since this gives N - 1 choices for the second page view and 2 for the third, the probability is
Let's generalize this to find the probability that you obtain k terms for some k between 1 and N. This happens precisely when the first k page views give new terms, but the (k + 1)st view gives one of the previous k terms. In order for the first k terms to all be distinct from one another, there are N – 1 choices for the second term, N – 2 for the third, and so on, so that there are N – (k – 1) choices for the kth page view. Then, since by this point you have seen k terms, this means there are k possible ways for the (k + 1)st view to be a repeat. Or, mathematically speaking, the probability that the first repeat occurs at the (k + 1)st page view is
In other words, if we have a value for k, we can determine what value of N makes this expression as large as possible - in other words, we can determine the most likely value of N, given k.
Let's get back to the matter at hand: discovering amazing terms for your favorite foods. I conducted this experiment, and recorded six unique slang terms; my seventh term was a repeat, so I stopped. Here is what I recorded:
raisins = old ass grapes
hot wings = lil' flapperz
shrimp = tiny ass lobster
ketchup = kanye blood
mountain dew = halo powerup
gum = chew chew trains
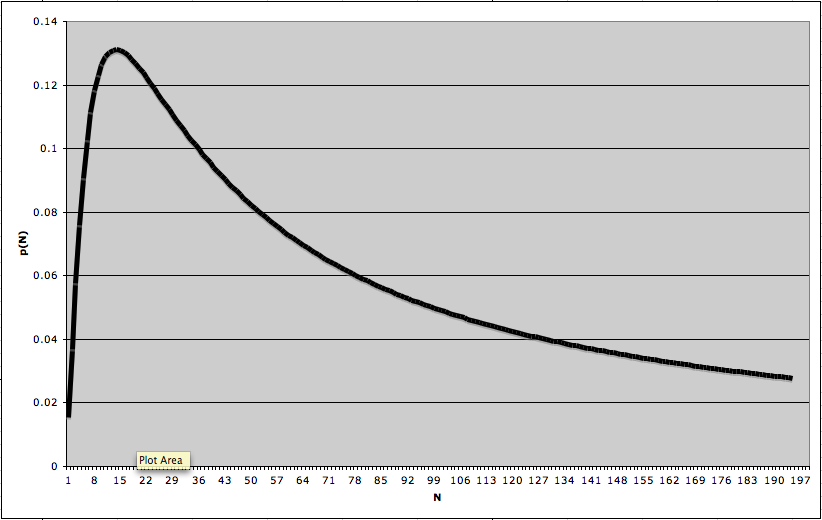
(Sadly, I did not come across one of my personal favorites, funyuns = stank rings.) Since I found 6 terms, I should take k = 6 in the above expression. This means I want to choose N so that is as large as possible. Let me simply call this expression p(N). By graphing p(N) for varying N (below is the graph for N between 6 and 200), we see that the maximum occurs at 19. So, based on this data, the best guess as to the number of slang terms on the website is 19.
{kind=link}

Note that this problem is not unique to this website. There are plenty of other internet destinations which use this same basic template. For example, here is one that will give you Charlie Sheen quotes (if you're into that sort of thing). In this case, I obtained 29 quotes before encountering my first repeat - this suggests that there are more Charlie Sheen quotes on the internet than Tom Haverford slang (the best estimate for N when k = 29 is, using the same argument as above, is an impressive 425). This is an imbalance that I hope will be corrected over time.
Of course, in practice one could gather more data before trying to estimate the number of Tom Haverford quotes — rather than stopping after the first repeat, one could stop after the second, or third, etc. This, in turn, would change the probability model, so I won't get into it here. I will say, though, that with a little bit more work one can show that the optimal choice of N given k distinct slang terms is the largest whole number such that
This is not exactly the simplest relationship between k and N, which makes a simple formula between the two values hard to come by. This is unfortunate, but is not such an issue in this case, since you are free to click to your heart's content, until you have claimed all the bounty that Tom's manner of speech has to offer.
Psst ... did you know I have a brand new website full of interactive stories? You can check it out here!
comments powered by Disqus